Overview
A comprehensive tool to evaluate how brands are mentioned and represented in Large Language Model (LLM) responses based on user intents you specify. This will tell you if your brand pops in AI responses when it should.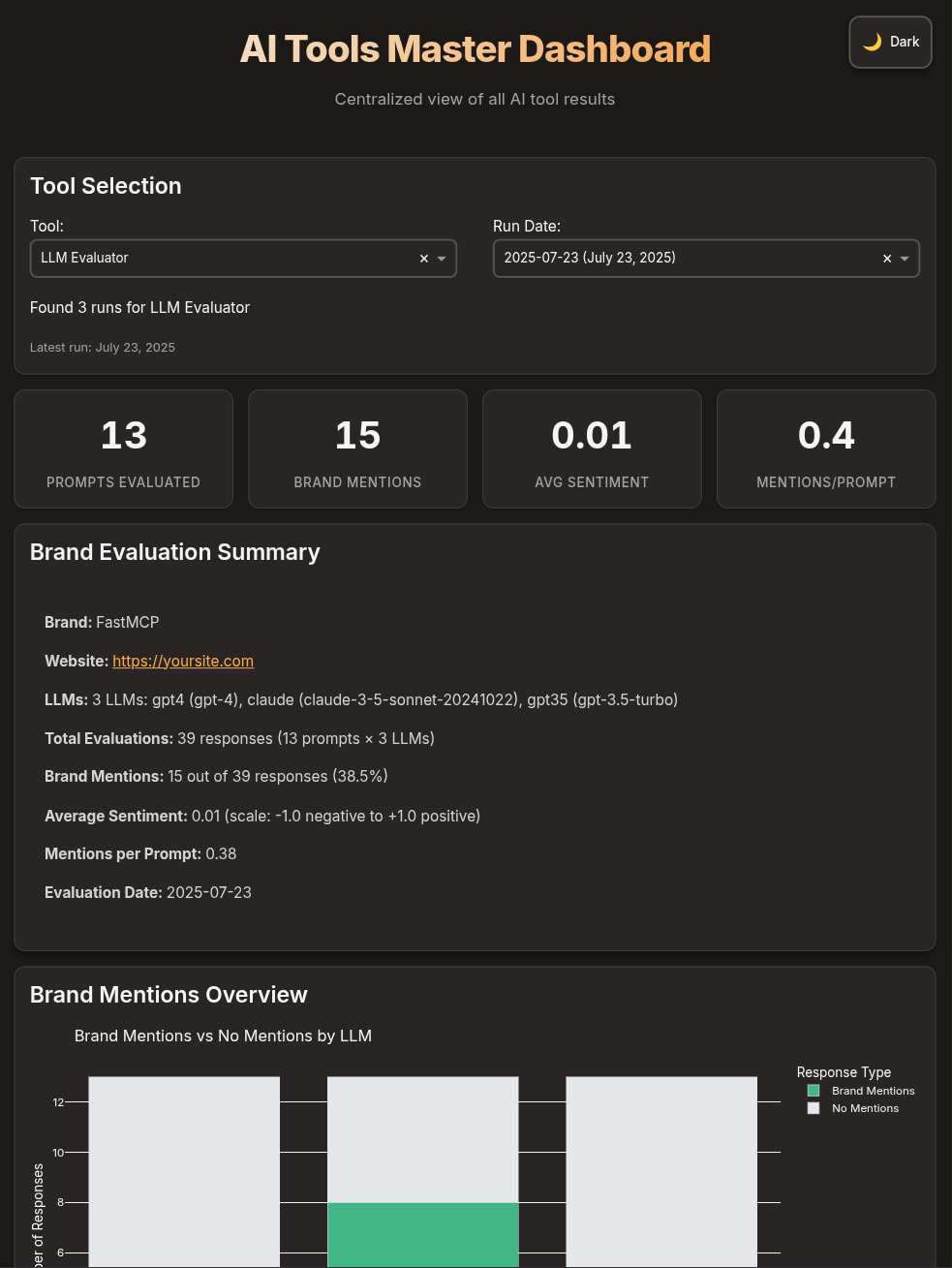
Key Features
Multi-LLM Evaluation
Evaluate brand mentions across multiple LLMs simultaneously with comparative
analysis
Sentiment Analysis
Hybrid sentiment analysis using TextBlob and LLM-based approaches for
accurate brand perception
Context Detection
Identifies whether mentions are recommendations, comparisons, examples, or
explanations
Dashboard Integration
Automatically integrates with the master dashboard for visual analysis and
reporting
Getting Started
Configure Environment
Set up your API keys and environment variables:
You’ll need API keys for OpenAI and/or Anthropic depending on which LLMs
you want to evaluate.
Create Configuration
Create a markdown configuration file with your brand information and
evaluation prompts:
Configuration
Brand Information Setup
Brand Information Setup
Configure your brand details for accurate detection and analysis:
- Name: Primary brand name to track
- Website: Official website URL for reference tracking
- Aliases: Alternative names or spellings of your brand
- Competitors: Competitor brands to track for comparison
Multi-LLM Configuration
Multi-LLM Configuration
Configure multiple LLMs for comparative analysis:Each LLM configuration includes:
- name: Unique identifier for the LLM
- provider: openai or anthropic
- model: Specific model name
- temperature: Response randomness (0-1)
- max_tokens: Maximum response length
Evaluation Prompts
Evaluation Prompts
Design prompts that naturally elicit brand mentions:
Evaluation Settings
Evaluation Settings
Fine-tune evaluation behavior and caching:
- Cache Responses: Enable response caching to reduce API costs
- Sentiment Analysis Method: “hybrid” combines TextBlob and LLM analysis
- Cache Expire Hours: How long to keep cached responses
- Batch Size: Number of prompts to process simultaneously
How It Works
Configuration Loading
The tool parses your markdown configuration file to extract brand
information, LLM settings, and evaluation prompts.
Multi-LLM Prompt Execution
Each prompt is sent to all configured LLMs simultaneously, with responses
cached to optimize API usage and costs.
Brand Mention Detection
Responses are analyzed to detect mentions of your brand, aliases, and
competitors using pattern matching and context analysis.
Sentiment Analysis
Each mention is analyzed for sentiment using a hybrid approach combining
TextBlob and LLM-based sentiment analysis for accuracy.
Context Classification
Mentions are classified by context (recommendation, comparison, example,
explanation) and position within the response.
Comparative Metrics
When multiple LLMs are used, additional metrics are calculated including
consensus scores and sentiment alignment between LLMs.
Output Structure
Results are organized in timestamped directories for easy tracking and comparison:- Dashboard Data
- Metrics Summary
- Detailed Results
The
dashboard-data.json file contains structured data optimized for the master dashboard:Dashboard Features
The evaluation results automatically integrate with the master dashboard, providing:Multi-LLM Comparison
Side-by-side comparison of how different LLMs mention and represent your
brand
Sentiment Analysis
Visual sentiment distribution with context and position tracking
Comparative Metrics
Consensus scores, sentiment alignment, and mention rate variance between
LLMs
Category Performance
Performance breakdown by prompt categories (Getting Started, Development,
etc.)
Command Line Reference
Path to the markdown configuration file containing brand information and
evaluation prompts
Launch the dashboard after evaluation completes
Launch dashboard without running evaluation (view existing results)
Launch dashboard for specific result date (format: YYYY-MM-DD)
Custom output directory for results (default: ./results)
Disable response caching for this evaluation run
Clear existing cache before running evaluation
Validate configuration without executing prompts
Show all available result dates
Set logging level (DEBUG, INFO, WARNING, ERROR)
Usage Examples
Metrics Explained
Brand Mention Metrics
- Total Mentions: Count of brand name appearances across all responses
- Mention Rate: Average mentions per prompt (mentions ÷ prompts)
- Position Distribution: Where mentions appear (beginning, middle, end of responses)
- Context Types: How the brand is mentioned (recommendation, comparison, example, explanation)
Sentiment Analysis
- Score Range: -1.0 (negative) to +1.0 (positive)
- Labels: Positive, Negative, Neutral, or Not Mentioned
- Method: Hybrid approach combining TextBlob and LLM-based sentiment analysis for improved accuracy
Multi-LLM Comparative Metrics
When evaluating multiple LLMs, additional insights are generated:Consensus Score
Percentage of prompts where all LLMs agree on mentioning (or not mentioning)
the brand
Sentiment Alignment
How closely LLMs agree on brand sentiment (0-100% agreement)
Mention Rate Variance
Statistical variance in mention rates across different LLMs
Performance Guidelines
- Enable Caching: Set
Cache Responses: trueto reuse responses and reduce API costs - Batch Processing: Use reasonable batch sizes (5-10 prompts) to optimize throughput
- Targeted Prompts: Design prompts that naturally elicit brand mentions in your domain
- Cache Management: Use
--clear-cacheonly when necessary to avoid unnecessary API calls
A typical evaluation with 13 prompts across 3 LLMs results in 39 API calls.
With caching enabled, subsequent runs with the same prompts cost nothing.
Troubleshooting
API Key Configuration
API Key Configuration
Problem: “No API key found” errors
Solution: Ensure your Check that the environment variables are properly loaded by running:
.env file contains valid API keys:Rate Limiting Issues
Rate Limiting Issues
Problem: API rate limit errors or timeouts
Solution: The tool implements automatic retries with exponential backoff. For persistent issues:
- Reduce batch size in your configuration
- Add delays between requests
- Check your API tier limits with your provider
- Use caching to minimize repeat requests
Cache Problems
Cache Problems
Problem: Stale or incorrect cached resultsSolution: Clear the cache and run fresh evaluation:You can also manually delete the cache directory:
Dashboard Integration
Dashboard Integration
Problem: Results not appearing in dashboardSolution: Ensure the evaluation completed successfully and check:
- Results directory contains
dashboard-data.json - Master dashboard is running from the correct tools directory
- No JSON formatting errors in the results file
Requirements
System Requirements
- Python: 3.8 or higher
- Memory: 512MB RAM minimum
- Storage: 100MB for cache and results
- Network: Internet connection for API access
API Requirements
- OpenAI API Key: For GPT models (gpt-4, gpt-3.5-turbo)
- Anthropic API Key: For Claude models (claude-3-opus, claude-3-sonnet)
Dependencies
Key Python packages (automatically installed):openai- OpenAI API clientanthropic- Anthropic API clienttextblob- Sentiment analysisdiskcache- Response cachingtqdm- Progress trackingpandas- Data processingplotly- Dashboard visualization
Integration
LLM Evaluator is designed to work seamlessly with the broader AI Tools Suite:- Master Dashboard: Automatic integration with shared visualization platform
- Intent Crawler: Compare brand mentions against discovered user intents
- Shared Infrastructure: Common caching, logging, and configuration patterns
- Cross-Tool Analysis: Combine insights from multiple evaluation tools
Advanced Usage
Programmatic Integration
Custom Sentiment Analysis
Contributing
When contributing to LLM Evaluator:- Maintain Dashboard Compatibility: Ensure changes don’t break dashboard integration
- Follow Multi-LLM Patterns: New features should support multiple LLM evaluation
- Add Comprehensive Logging: Use the existing logging framework for debugging
- Update Documentation: Keep this MDX file current with new features
- Test with Real APIs: Validate changes with actual LLM providers
- Consider Costs: Be mindful of API usage in new features
Future Roadmap
- Additional LLM Providers: Support for Cohere, AI21, and other providers
- Advanced Analytics: Statistical significance testing for comparative metrics
- Real-time Monitoring: Continuous brand mention tracking across time
- Custom Scoring Models: User-defined sentiment and relevance scoring
- Export Capabilities: PDF reports and data export formats
- A/B Testing Framework: Compare different prompt strategies
Part of the Airbais AI Tools Suite - Comprehensive tools for AI-powered business intelligence and brand analysis.