Overview
GRASP Evaluator is a comprehensive assessment tool that evaluates website content quality across five weighted dimensions to optimize for LLM understanding and response generation.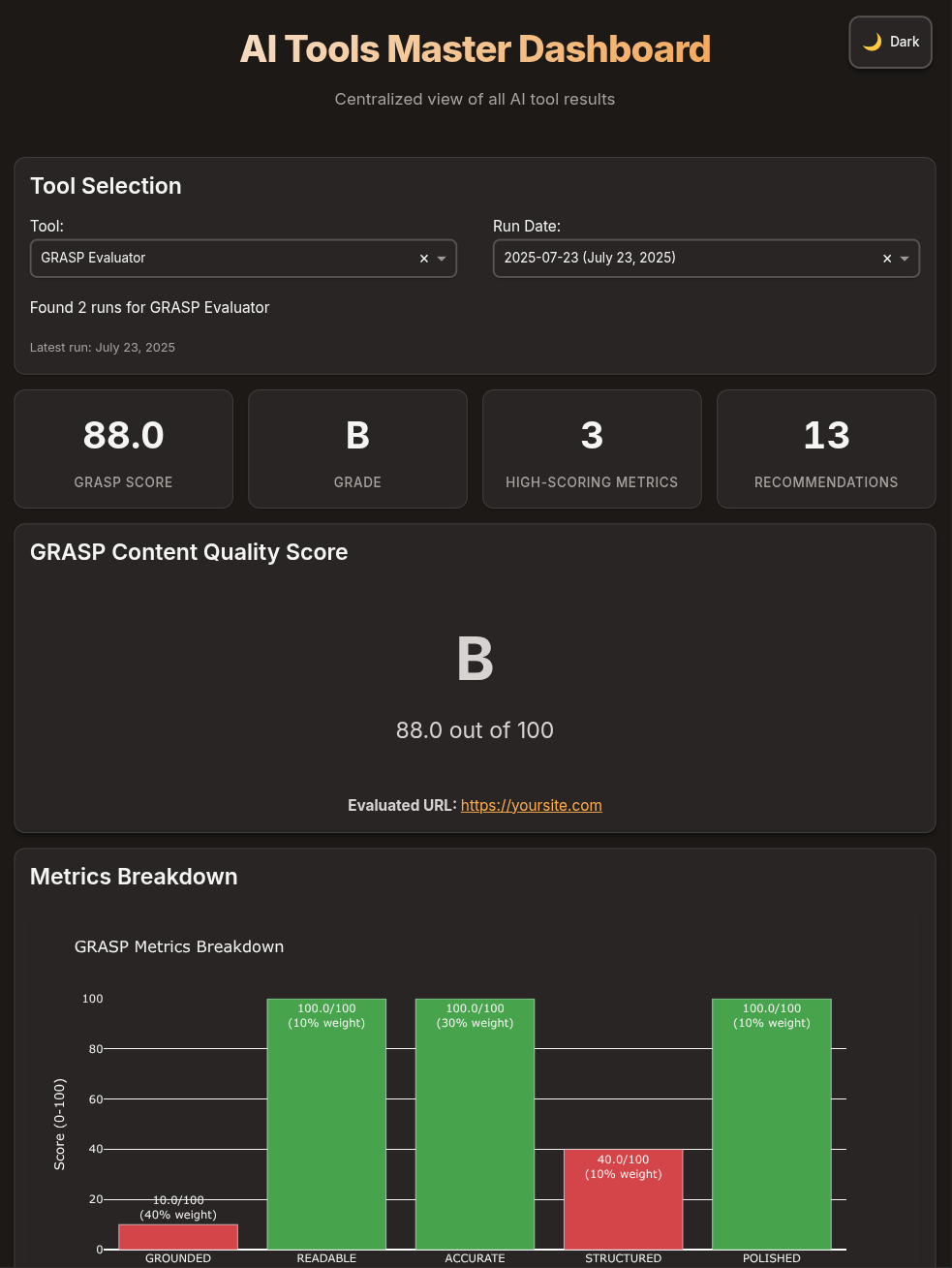
Grounded
Evaluates content alignment with customer intents using AI
Readability
Analyzes reading level for target audience matching
Accuracy
Assesses content freshness as a way to determine accuracy
Structure
Evaluates semantic HTML for optimal LLM consumption
Polish
Evaluates content for grammar, spelling, and style
Installation
Configuration
Set up your OpenAI API key in the.env file:
.env
Quick Start
Configuration File
Customize evaluation parameters inconfig/grasp_config.yaml:
grasp_config.yaml
Understanding Your Results
GRASP Score Calculation
The overall GRASP score is calculated using weighted metrics:Grounded (40% weight)
Grounded (40% weight)
Range: 0-10 points
- 9-10: Content provides comprehensive answers to customer intents
- 7-8: Good content support with minor gaps
- 5-6: Partial information with noticeable gaps
- 3-4: Limited relevant information
- 1-2: Little to no relevant information
Readable (10% weight)
Readable (10% weight)
Result: Pass/Fail
- Pass: Content reading level matches target audience (±1 grade level)
- Fail: Content is too complex or too simple for target audience
- Elementary: Grades 3-6
- High School: Grades 7-12
- College: Grades 13-16
- General Public: Grades 6-8
Accurate (30% weight)
Accurate (30% weight)
Ratings: High/Medium/Low
- High: Content updated within 6 months
- Medium: Content updated within 1 year
- Low: Content older than 1 year or no date found
- Meta tags
- Schema.org markup
- Time elements
- Content patterns
- HTTP headers
Structured (10% weight)
Structured (10% weight)
Ratings: Excellent/Good/Fair/Poor/Very PoorEvaluates:
- Heading hierarchy (h1-h6)
- Semantic HTML elements
- Lists and tables
- Schema.org markup
- Open Graph tags
Polished (10% weight)
Polished (10% weight)
Ratings: Excellent/Good/Fair/Poor/Very PoorChecks:
- Grammar and spelling errors
- Punctuation issues
- Style and readability
- Error rate calculation
Grade Scale
A Grade
90-100 points (Excellent)
B Grade
80-89 points (Good)
C Grade
70-79 points (Fair)
D Grade
60-69 points (Poor)
Detailed Evaluations
Grounded Evaluation
The grounded metric uses AI to evaluate content quality by:- Intent Processing: Takes customer intents from configuration
- Answer Generation: Uses content to answer each intent
- Quality Assessment: Evaluates answer completeness and accuracy
- Scoring: Provides 0-10 score based on content support
Readable Evaluation
Reading level assessment using multiple formulas:- Flesch-Kincaid Grade Level
- Gunning Fog Index
- Coleman-Liau Index
Accurate Evaluation
Since only the content creator can really know if the content is accurate, we use freshness as a proxy for accuracy. The idea is that if the content is updated regularly, it’s far more likely to be accurate than stale content. We look at content freshness from multiple sources:Structured Evaluation
HTML structure analysis covering:- Heading Hierarchy: Proper h1-h6 usage and nesting
- Semantic Elements: main, article, section, header, footer, nav
- Data Structures: Lists, tables with proper markup
- Schema Markup: JSON-LD, microdata, RDFa
- Meta Properties: Open Graph, Twitter Cards
Polished Evaluation
- AI-Powered (Default)
- Rule-Based (Fallback)
Uses OpenAI API for comprehensive analysis:
- Grammar checking
- Spelling verification
- Style assessment
- Error rate calculation
Dashboard Integration
GRASP evaluation results automatically integrate with the master dashboard:Score Visualization
Interactive charts showing metric breakdown and trends
Detailed Analysis
Comprehensive metric explanations and recommendations
Historical Tracking
Track improvements over time across evaluations
Recommendation Engine
Actionable suggestions for content improvement
Output Files
Results are saved in timestamped directories:API Requirements
Rate Limits: The evaluator respects API limits with:- Built-in batching for intents
- Configurable request delays
- Automatic retry logic
Troubleshooting
Missing API Key
Missing API Key
.env file in the tools directory.Rate Limiting
Rate Limiting
- Reduce
batch_sizein configuration - Increase
retry_delayin API settings - Use fewer customer intents
Content Too Long
Content Too Long
max_content_length in grounded configuration.No Date Found
No Date Found
- Add
<meta name="last-modified">tags - Include
<time>elements withdatetimeattributes - Add schema.org
dateModifiedproperties
Advanced Usage
Custom Intents
Define specific customer intents for your business:Multiple Target Audiences
Configure different reading levels:Custom Freshness Thresholds
Adjust based on your content update frequency:Debug Mode
Run with verbose logging:Best Practices
Content Strategy
- Align content with specific customer intents
- Maintain appropriate reading level
- Update content regularly
- Use semantic HTML structure
Technical Implementation
- Add proper meta tags
- Include schema.org markup
- Use semantic HTML5 elements
- Implement proper heading hierarchy
Contributing
This tool is part of the Airbais suite. For contributions:- Follow existing code patterns
- Add tests for new features
- Update documentation
- Ensure dashboard compatibility
Support
For issues and questions, check the troubleshooting section or consult the technical documentation.